Team42 Milestone
video slides
About Proposal Feedback
Thanks to TA Mingyang Wang, for some questions and suggestions on our project's proposal. Here are some answers:
About our input text: If we were to use a text prompt format, we would use a search-like approach rather than LLM, which is overly complex and there doesn't seem to be much work currently combining LLM and 3D generation. But right now we're not sure if we want to combine it with a text prompt.
About feature transformation: We haven't finalized what we're going to do because there are a lot of existing methods that deal with it differently. We have reproduced various efforts and have not yet decided which one we will adopt.
About clothes: The clothes shape will be already baked into the model(it depends on the picture entered at the beginning and there will be no physics simulation). It's a pity we couldn't include a physics simulation, because the reconstruction alone would have been complicated.
Our Progress
We originally intended to implement Text-Driven 3D Human Generation. we found a very relevant paper: HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting, and plan to reproduce this. However, after 2-3 days of trying hard, we realized that there were a lot of problems with this repository: the environment configuration must cause some conflicts, some plugins can't be installed on our machine...
We turn our attention to a piece of work ECON that does not use any Nerf or Gaussian methods, but instead recovers the entire reconstruction from a monocular image(no text prompt) by a series of methods such as estimating normals, depths, etc., as well as by combining the SMPL prior for the human body. We ran this work successfully and here are some results:

On the left are the images entered, and on the right are the people observed from all angles after the reconstruction.
However, this method is more "traditional" (and actually quite new, but scene reconstruction methods such as Gaussian splatting seem to be a bit more up-to-date). We looked at the Animatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars method, which utilizes Gaussian splatting to reconstruct character action scenes. We successfully ran this work:



Above is the result of reconstructing the animated human body.
We then turn our attention to another piece of work: Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians, which focuses on reconstructing dynamic head avatar, could be driven by input multi-view videos. Our test shows that the results reach high-fidelity. The pipeline is shown here:
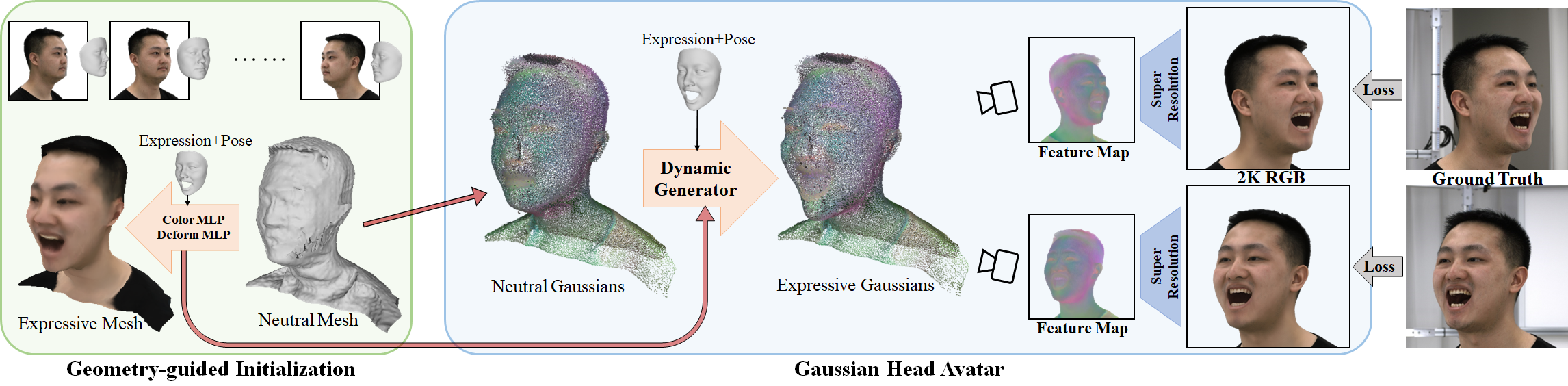
They first optimize the guidance model including a neutral mesh, a deformation MLP and a color MLP, yielding a expressive mesh head avatar. The mesh and the MLPs would be the initialization of the Gaussian model and the dynamic generator respectively. The optimizing process is shown below.

Then they use the Gaussian model and the dynamic generator to generate expressive Gaussian head, feeding to a super-resolution up-sampling network renders a 2K RGB image, which is compared with the ground truth to get the loss. The first 7% of the process is shown below:

Here shown are two images of the rendered result of trained raw Gaussian head (left) and high-resolution result (right). The result reaches high-fidelity.


After training, the Gaussian avatar can be reenacted by expression coefficients as shown below.

We tried to search for more literature related to Text-Driven 3D Human Generation on various platforms such as Google Scholar and found that since text-driven related content is still relatively new, and at the same time, 3d Gaussian splatting has just been proposed, there is very little work combining the two and it is difficult to learn from it. We thought about whether we could do something that does not use text-driven generation, but rather single/multiple eye reconstruction, which has more work to draw on.
Reflection and update plan
We are now confined to the work of reproducing the various methods, and do not yet know what our predominant course will be. We will try to finalize our route over the next week.
What we're doing is more difficult, and we're not sure we can innovate on replicating what others have done. We will continue to explore.