Final Project Report
Jian Yu, Xiaoyu Zhu, Xinzhe Wei, Zimo Fan
Our video(click it!):

1 Abstract
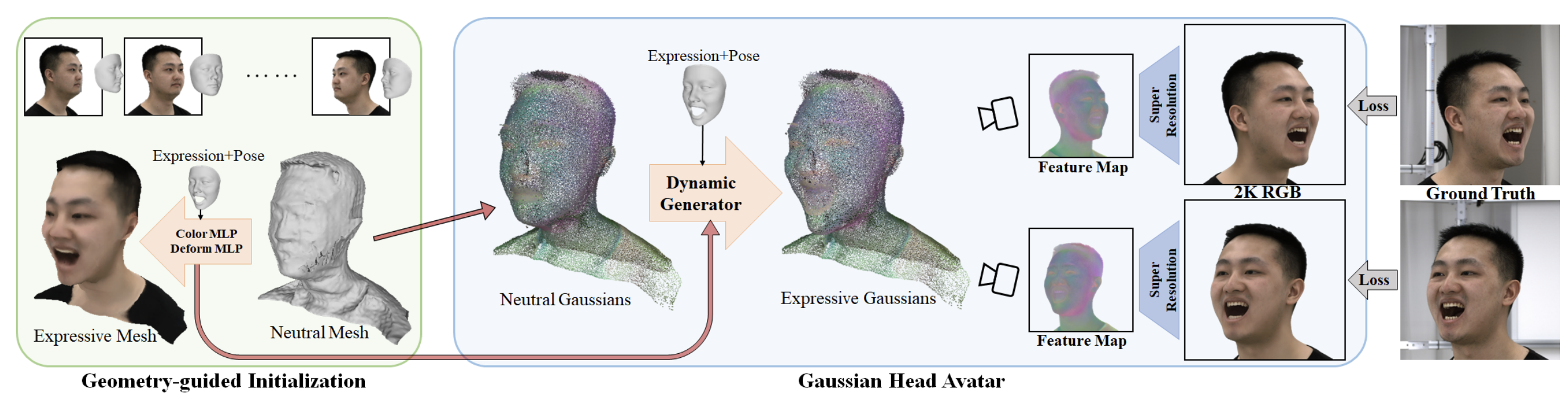
Our project aimed to create high-fidelity 3D head avatars using a combination of neutral 3D Gaussians and a fully leaned MLP-based deformation field. our method can capture intricate dynamic details while maintaining expression precision. What's more, for the stability and convergence of the training procedure, we devise a well-designed initialization strategy guided by geometry, leveraging implicit SDF and Deep Marching Tetrahedra.
2 Technical Approach
We begin by removing the background from each image and simultaneously estimating the 3DMM model, 3D facial landmarks, and expression coefficients for every frame. During the initialization phase in 2.1, we reconstruct a neutral geometry based on Signed Distance Fields (SDF). Additionally, we refine a deformation MLP and a color MLP using training data to create a guidance model. Subsequently, we initialize the neutral Gaussians using the neutral mesh extracted through DMTet, while the deformation and color MLPs are also inherited from this stage.



Above is the preprocessing on Jian Yu's face.
Moving on to the training phase in Section 2.2, we utilize the dynamic generator to deform the neutral Gaussians to the target expression, leveraging the driving expression coefficients as conditions.
Ultimately, with a specified camera perspective, the expressive Gaussians undergo rendering to produce a feature map. This feature map subsequently serves as input to the convolutional super-resolution network, tasked with generating high-resolution avatar images. The optimization of the entire model occurs under the guidance of supervision from multi-view RGB videos.
2.1 Geometry-guided Initialization
We are familiar with how to start neural networks but Gaussians are quite different. Random initialization will be hard to converge.
To overcome this, we propose utilizing an implicit Signed Distance Field (SDF) representation and Deep Marching Tetrahedra (DMTet) to reconstruct a neutral mesh for Gaussian position initialization. Furthermore, rough optimization is applied to the color and deformation MLPs.
We build MLPs to initialize parameters
Offset regularization
Landmark regularization
Laplacian regularization
The overall loss function is formulated as:
Where
Then, we use the optimized results to attributes:
2.2 Training
2.2.1 Training Pipeline
To compute loss, in each iteration, we first generate the head avatar, then we render a 32-channel image with 512 resolution
2.2.2 Loss Function
2.3 Avatar Representation
Our goal is to generate a dynamic head avatar controlled by expression coefficients. To achieve this, we represent the head avatar as dynamic 3D Gaussians conditioned on expressions. To accommodate dynamic changes, we incorporate expression coefficients and head pose as inputs to the head avatar model, which then outputs the position and other attributes of the Gaussians accordingly.
This is the pipeline of the paper we refer to:
Firstly, we build a neutral Gaussian model with expression-independent attributes:
Then, we will further explain how to update
For
The two
and
Instead of using linear function, we also tried to add some sigmoid-like function on it. That's because:
Speaking from experience with masking and weight drawing, the general weight matrix is very sparse, with epidermal vertices overwhelmingly influenced by the nearest bone. Skeleton manipulation of meshes is similar to mesh manipulation of Gaussians.
It may be more in keeping with the body's natural.
For
For
Lastly, we need to transform from canonical space to real world space. Only direction related variables need to be changed. So we have
2.4 Problems
The training process was too slow, and although our results were trained on an existing dataset, it was too late to train it after we created our own data.
The work we referenced is so advanced (CVPR 2024) that it's hard for us to make big improvements on it. We only modified some parameters to make them more reasonable and tried to create our own dataset.
2.5 Lessons Learned
For the final project, our team has extensively studied the relevant content. First, we explored the grid-based human body model, and we researched the classic work of SMPL from the Max Planck Institute. SMPL appears to be a complex work with many abstract mathematical notations and involves a lot of prerequisite knowledge in computer graphics. However, combining the knowledge we learned in the course, we gradually understood that it is essentially a mesh model implemented using blend shapes technology, considering the influence of Shape and Pose on the standard Template through a technique called linear blend skinning (LBS). The following image is the slide we prepared for our discussion. These are the footprints of our learning process👣👣👣.

Next is the novel scene representation technique: 3D Gaussian splatting (3DGS). 3DGS expresses the scene by optimizing several small Gaussian distributions and renders them using splatting, a rasterization technique. Each Gaussian distribution not only has its mean (position) and variance (size and shape) attributes but also carries opacity (α) and spherical harmonic functions to represent the three-channel color values in different views. Since the rendering process of 3DGS involves rasterization instead of ray tracing and the original author utilized CUDA and parallelized the rendering process using multiple threads, the efficiency of rendering 3DGS scenes has been significantly optimized, resulting in real-time performance. Moreover, from an effectiveness perspective, 3DGS exhibits a strong capability in scene representation.
We tried to reproduce the latest CVPR work. Even though it was difficult, it was fun. We created COOL avatars and found our joy in code and graphics.
When making adjustments to parameters, thorough deliberation is paramount, particularly given the extensive training times characteristic of a model of such magnitude. Deviating from the optimal direction could lead to significant time wastage, as rectifying errors and rerunning experiments can be exceptionally time-consuming.
Furthermore, it's imperative to craft a comprehensive and flexible plan with generous time allocations. Unforeseen complications are inevitable, and they often demand more time than initially anticipated. For example, delving into the intricacies of the original codebase can prove to be far more challenging than initially imagined. Additionally, there can be a considerable disparity between the current state of the art in research papers and the knowledge base at our disposal. Such disparities may necessitate additional time for learning and adaptation, underscoring the importance of a well-padded timeline.
3 Results
We first use images and cameras to model the head in existing dataset:

Then convert it into Gaussian model:

Use another person's head to reenactment our avatar:

The right side is the trained avatar, the left side is making a new movement making the right head mimic the left one.
4 References
Papers
Xu, Yuelang, et al. "Gaussian head avatar: Ultra high-fidelity head avatar via dynamic Gaussians." arXiv preprint arXiv:2312.03029 (2023).
Gerig, Thomas, et al. "Morphable face models-an open framework." 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018). IEEE, 2018.
Websites
https://github.com/YuelangX/Gaussian-Head-Avatar
https://github.com/YuelangX/Multiview-3DMM-Fitting/tree/main
5 Contributions from each team member
Jian Yu: Do research on the topic, Reproduction of possible work, Try to make our own dataset, Polish the final report
Xinzhe Wei: Do research on the topic, Reproduction of possible work, Train on the exist dataset, Polish the final report
Xiaoyu Zhu: Do research on the topic, Reproduction of possible work, Try to make our own dataset, Polish the final report
Zimo Fan: Do research on the topic, Reproduction of possible work, Drafting of the first version of the final report, Polish the final report